Blog
Articles about computational science and data science, neuroscience, and open source solutions. Personal stories are filed under Weekend Stories. Browse all topics here. All posts are CC BY-NC-SA licensed unless otherwise stated. Feel free to share, remix, and adapt the content as long as you give appropriate credit and distribute your contributions under the same license.
tags · RSS · Mastodon · simple view · page 1/20
Short-term depression (STD) and short-term facilitation (STF)
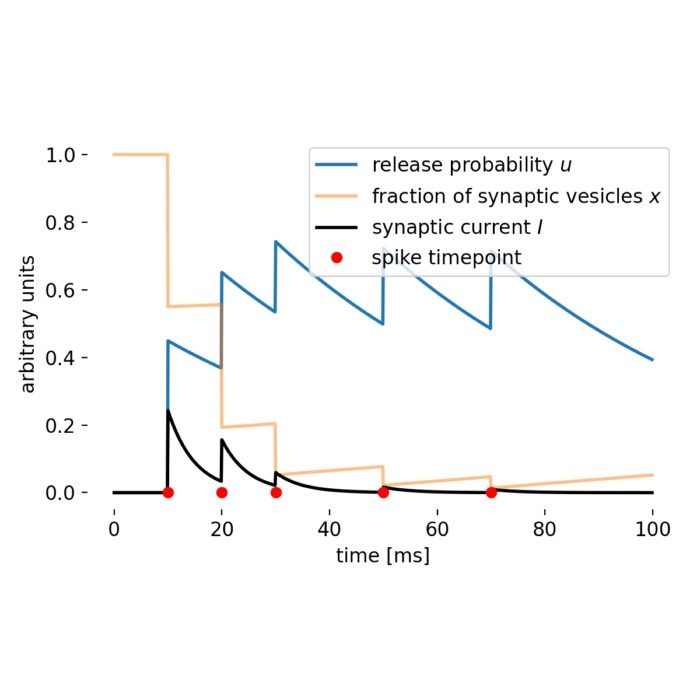
Short-term depression (STD) and short-term facilitation (STF) are forms of short-term synaptic plasticity, which refer to temporary changes in the strength of synaptic transmission. These mechanisms are critical for the dynamic regulation of synaptic activity and play important roles in neural processing and information transmission. Here’s a brief overview of STD and STF, and how they can be implemented in computational models of neural networks.
Virchow’s Cellularpathologie: A foundational work in the history of medicine and neuroscience

Rudolf Virchow is famous for his contributions to medicine and pathology, with his most influential work being Cellularpathologie, published in 1858. In this post, I share some insights from engaging with this seminal work, which laid the conceptual foundation for modern pathology and had profound implications for how disease, cellular life, and the nervous system were understood.
Helmholtz’s dissertation on the nervous system: A forgotten early contribution to neuroscience

While Hermann von Helmholtz is widely known for his foundational contributions to physics, his early scientific work was actually focused on the nervous system. In this post, I share insights from reading Helmholtz’s 1842 dissertation, which was recently translated from Latin into English by Helmut Kettenmann and colleagues. The dissertation reveals Helmholtz’s detailed anatomical study of invertebrate nervous systems, conducted at a time when the conceptual distinction between neurons and glial cells did not yet exist.
Clopath plasticity rule
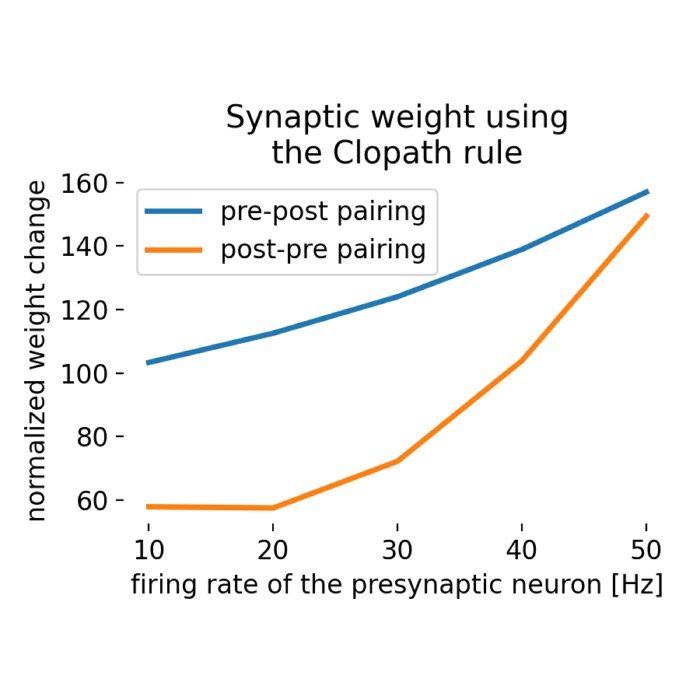
The Clopath learning rule or the Clopath synaptic plasticity rule is a biophysically inspired model of synaptic plasticity that extends traditional Hebbian learning by incorporating both spike-timing-dependent plasticity (STDP) and voltage-dependent plasticity mechanisms. This rule was introduced by Claudia Clopath et al. in 2010 to address some of the limitations of classical STDP models, providing a more accurate representation of synaptic changes observed in biological neurons.
Urbanczik-Senn plasticity
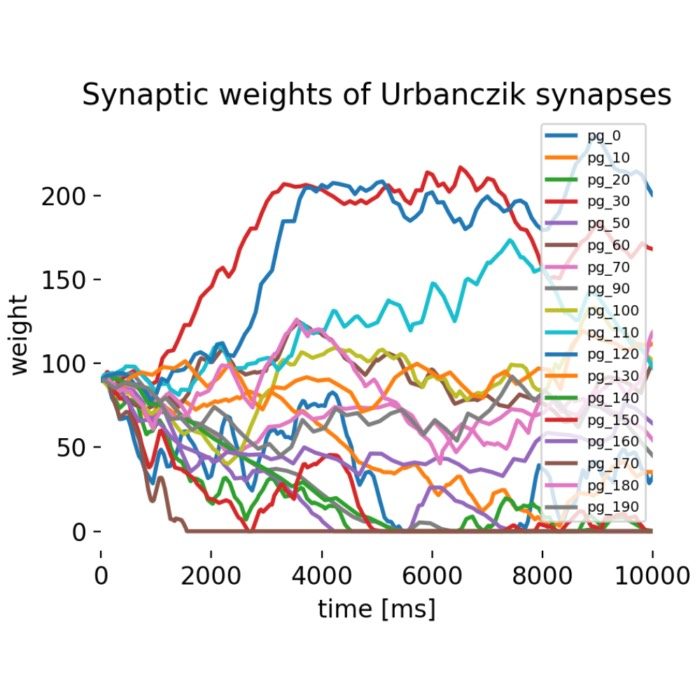
The Urbanczik-Senn plasticity model proposes a learning rule for dendritic synapses in a simplified compartmental neuron model. This rule extends traditional spike-timing-dependent plasticity (STDP) by incorporating the local dendritic potential as a crucial third factor, alongside pre- and postsynaptic spike timings. In this post, we briefly introduce the Urbanczik-Senn plasticity model and discuss its implications for neural computation and learning.
Implementing a minimal spiking neural network for MNIST pattern recognition using nervos
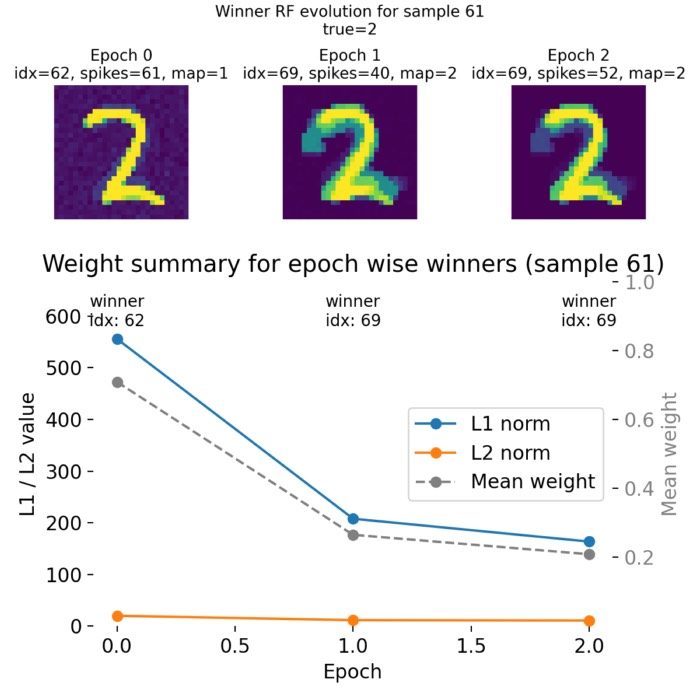
In this post, we use the open source spiking neural network (SNN) framework nervos to implement a minimal two layer SNN for pattern recognition on the MNIST dataset. We analyze how the network learns to classify digits through spike timing dependent plasticity (STDP) and how the synaptic weights evolve during training.
Spike-timing-dependent plasticity (STDP)
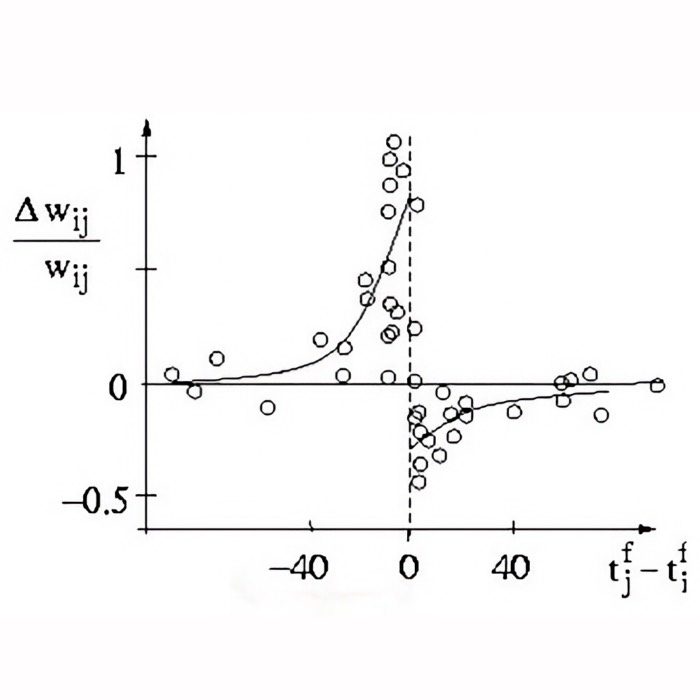
Another frequently used term in computational neuroscience is spike-timing-dependent plasticity or STDP. STDP is a form of synaptic plasticity that adjusts the strength of synaptic connections between neurons based on the relative timing of pre- and postsynaptic spikes. In this post, we briefly explore the concept of STDP and how it is implemented in neural modeling.
Revisiting the Moore’s law of Neuroscience, 15 years later
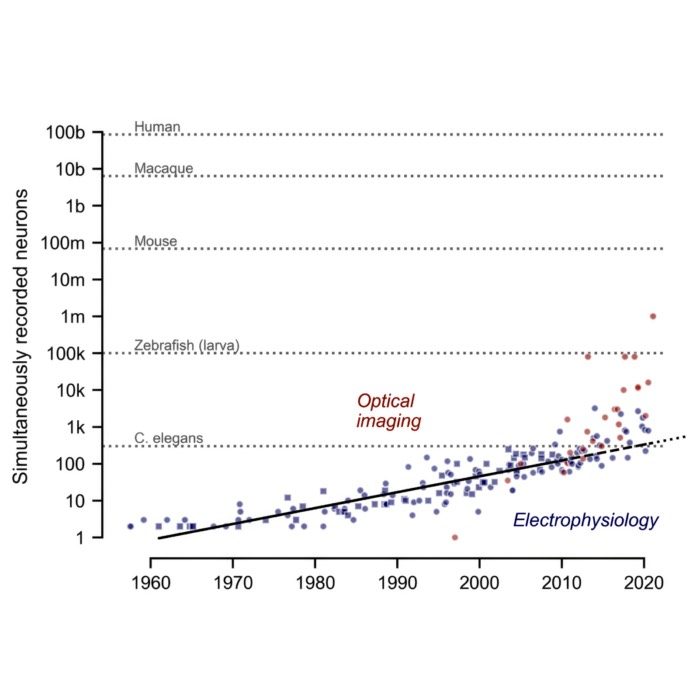
Just figured out that neuroscience appears to have its own version of Moore’s law, at least when it comes to the number of neurons that can be recorded simultaneously. This empirical scaling has profound implications for data analysis, modeling, and theory in computational neuroscience. In this post, we briefly review the original 2011 paper by Stevenson and Kording and reflect on its relevance today.
Neural Dynamics: A definitional perspective
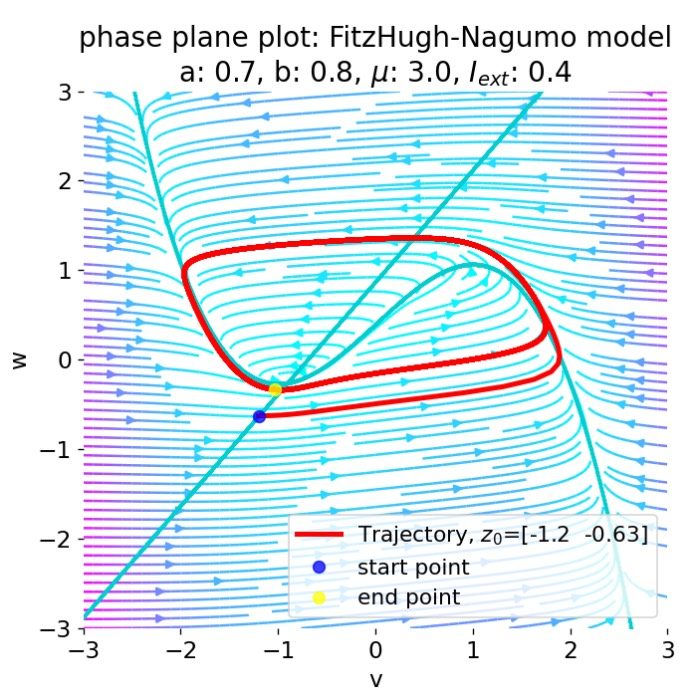
Neural dynamics is a subfield of computational neuroscience that focuses on the time dependent evolution of neural activity and the mathematical structures that govern it. This post provides a definitional overview of neural dynamics, situating it within the broader context of computational neuroscience and outlining its key themes, methods, and historical developments.
Neural plasticity and learning: A computational perspective
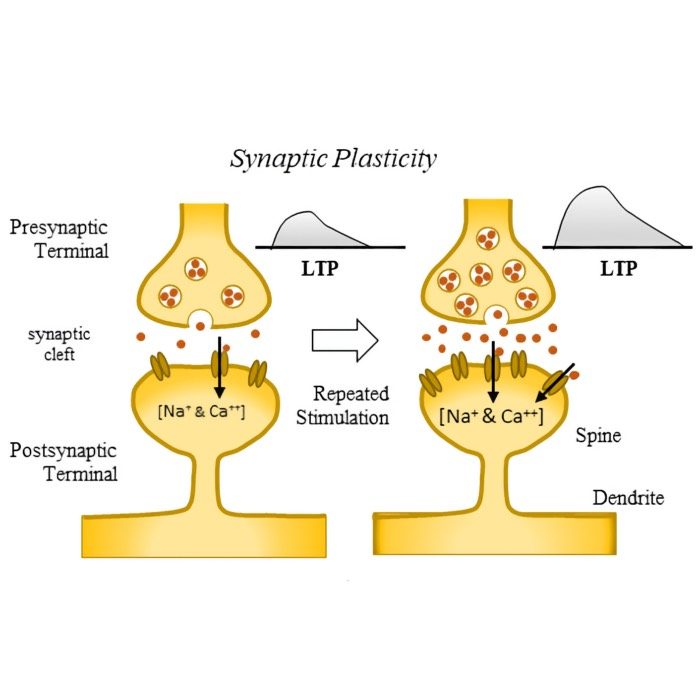
After discussing structural plasticity in the previous post, we now take a broader look at neural plasticity and learning from a computational perspective. What are the main forms of plasticity, how do they relate to learning, and how can we formalize these concepts in models of neural dynamics? In this post, we explore these questions and propose a unifying framework.